Candy
The introduction of a new programming language
In statically typed programming languages, you define what values can go into variables and functions. Usually, you do this using types that are defined constructively – some types are built-in and new types can be created by combining other types.
Mathematical functions don't work on types, but sets. They are slightly different: Sets are defined by which values are inside or outside of them.
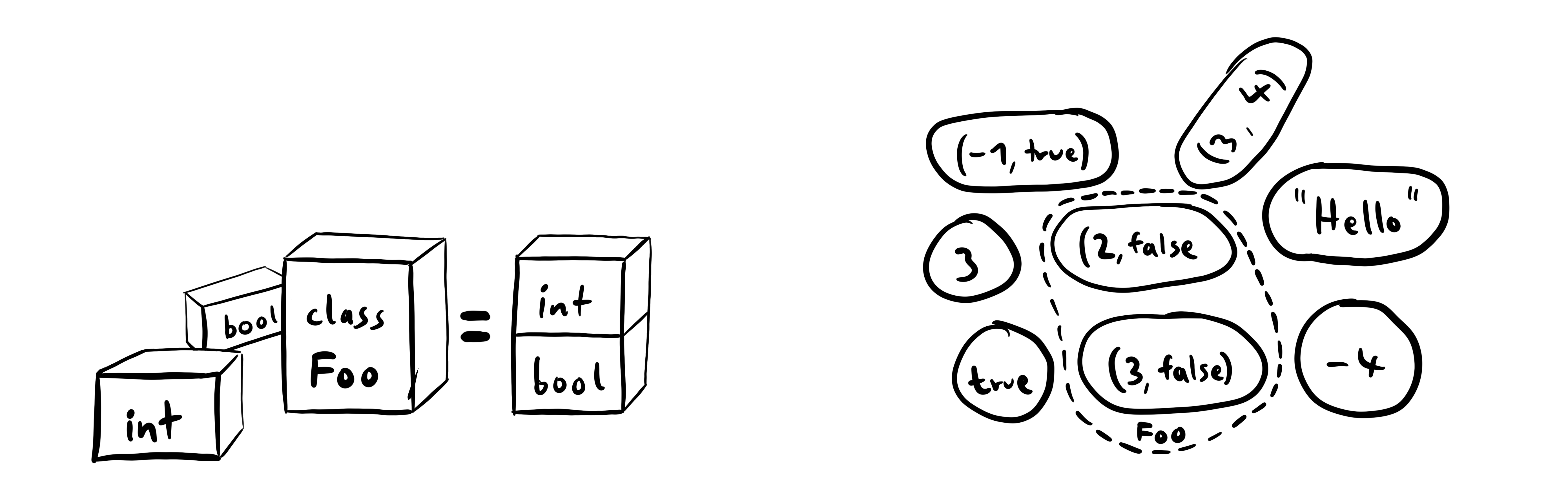
Mathematical sets can be much more nuanced than constructive types. For example, you can define a set containing only even numbers. In most programming languages, types can't encode such information.
That's why we asked ourselves what a language would look like where functions work more like mathematical ones. The result is Candy – a programming language where requirements of functions are specified with normal code and checked during runtime.
The concrete syntax is not the focus of this article (you can check out the language repository on GitHub if you're interested). Instead, I want to focus on the semantics of a feature unique to Candy: needs.
Needs
In Candy, functions can specify their requirements by calling a built-in function called
For example, this function
increment a =
needs ( isInt a )
int . add a 1
three = increment 2
Here,
While this approach is more verbose than traditional types, it's also more powerful. For example, you could also change the function so that it only accepts even integers:
increment a =
needs ( isInt a )
needs ( int . isEven a )
int . add a 1
How This Compares to Other Approaches
Although Candy is a dynamic language and
As you type, you immediately get feedback. The tooling tells you about unhandled edge cases and shows example values for functions. For example, for a factorize function, you see factorizations of numbers next to the function signature:
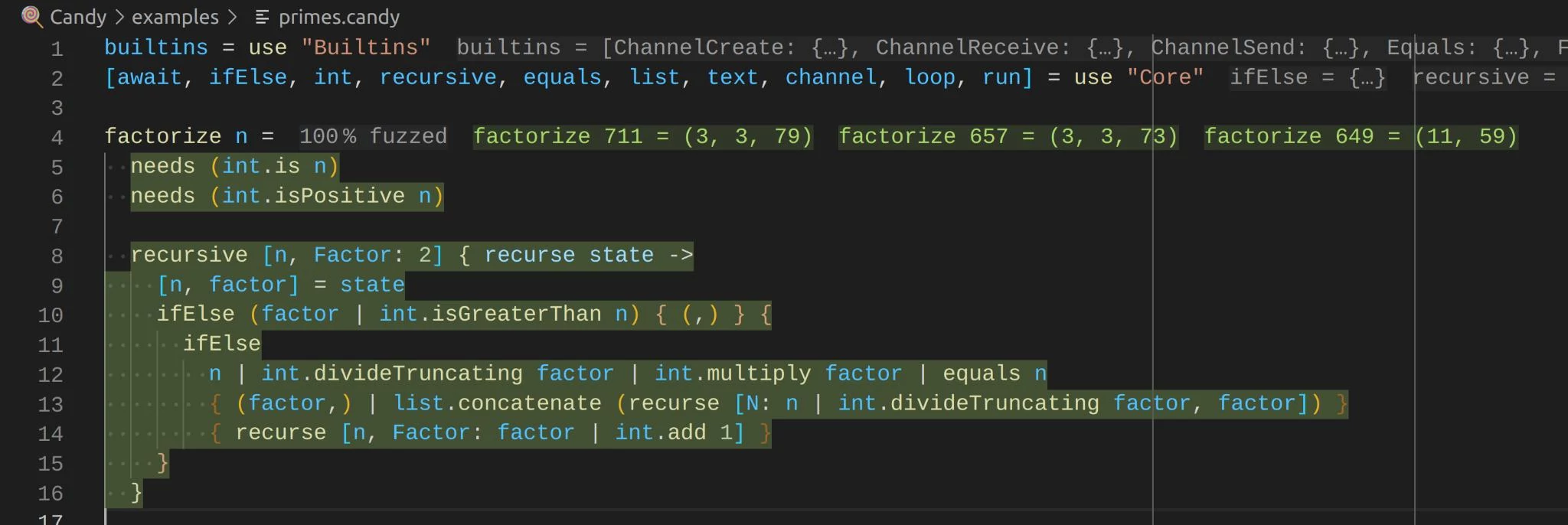
Of course, similar approaches already exist. Most notably, contracts allow checking arbitrary statements at the beginning and end of functions. However, needs can be placed anywhere inside functions and interwoven with the execution.
# only accepts URLs to servers that return JSON
fetchJson url =
needs ( isUrl url )
response = fetch url
needs ( isJson response )
...
How does it work?
Candy uses two ingredients to get good tooling despite being very dynamic: Precise semantics of needs and fuzzing when editing.
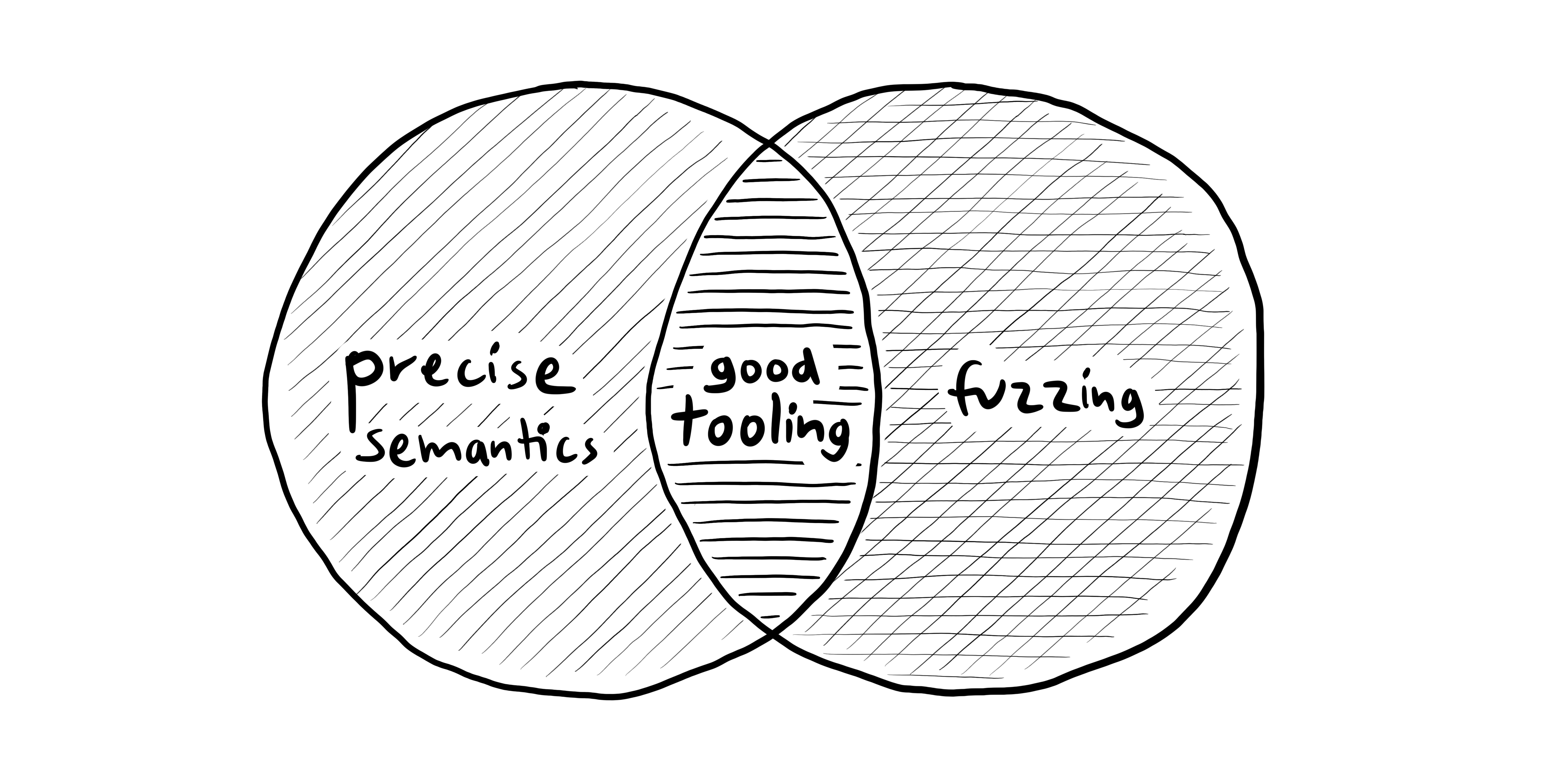
Precise Semantics
Panics in Candy are not like exceptions and crashes in other languages. Every panic of a Candy program can be attributed to a single responsible call in the code.
Needs are a fundamental building block for that. Although they look like function calls, they are not. Compare the following scenarios:
foo a =
needs ( isInt a )
4
# vs.
foo a = bar a
bar a =
needs ( isInt a )
4
In the first example, the caller of
Would
As a result, the compiler handles needs in a special way. As the program goes from source code throughout the compilation stages, it converts needs into calls that pass around references to the original source code as explicit responsibilities.
Fuzzing
Fuzzing refers to running code with many random inputs and seeing what happens. There's lots of existing literature about fuzzing, but what makes Candy special is that fuzzing works not only on the scope of entire programs, but even for individual functions.
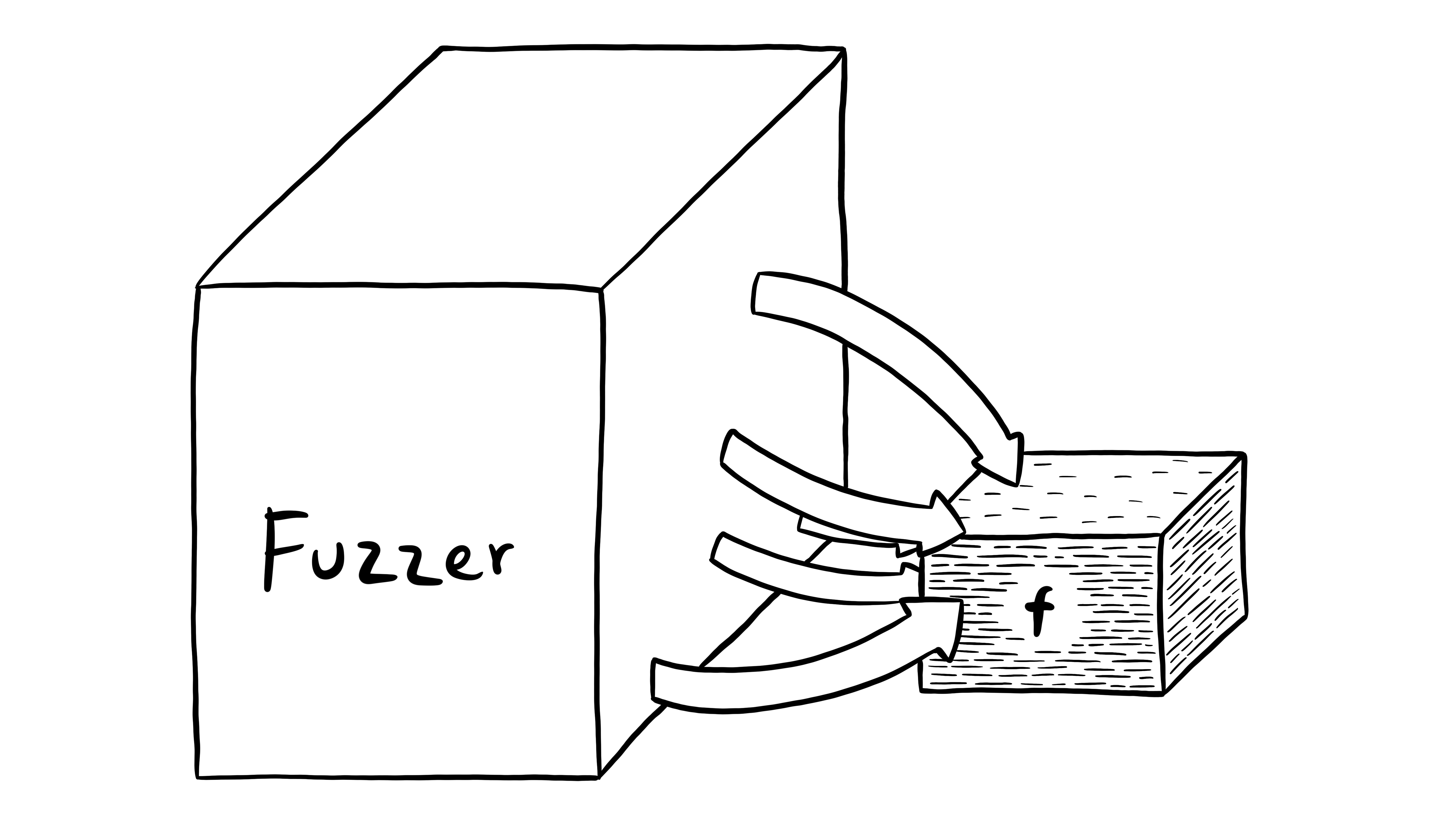
Because in Candy, every panic also attributes fault, running a function results in either of the following results:
The function returns a value. The fuzzer found an example that successfully runs through the function. This input can be displayed in the IDE as an example input.
A needs of the function wasn't fulfilled. The fuzzer is at fault – it called the function with invalid arguments. It should just try other inputs.
The function called another function and didn't fulfill its needs. The code of the function itself is wrong and the IDE shows an error at the exact call that is at fault.
Evaluation
Programming in Candy feels like working a statically typed language. You get feedback about your code right as you type it.
To me, the usefulness of example values cannot be overstated. When browsing some code, seeing how a function behaves for concrete inputs is quite useful.
When working in Candy, errors are easy to grasp. You always have a failing input that serves as an entry point into debugging. Also, rather than reporting a generic type mismatch, custom error messages can make the experience natural. I'm especially curious how package authors will use custom errors to tailor the IDE experience.
The primary hindrance of using Candy productively right now is its performance. We have ideas on how to make the VM faster, but eliminating and optimizing out needs requires some advanced compile-time analyses.