Chunky
A database layer
Chest's lowest abstraction layer is called Chunky. In the end, Chest should somehow store all data in a file, something like
A key question is how to deal with mutating data: If we need to insert some data "in the middle" of the database, we don't want to re-write everything that comes after it. Files are a linear stream of bytes, and that doesn't quite fit our use case. So, the Chunky layer offers an abstraction from that.
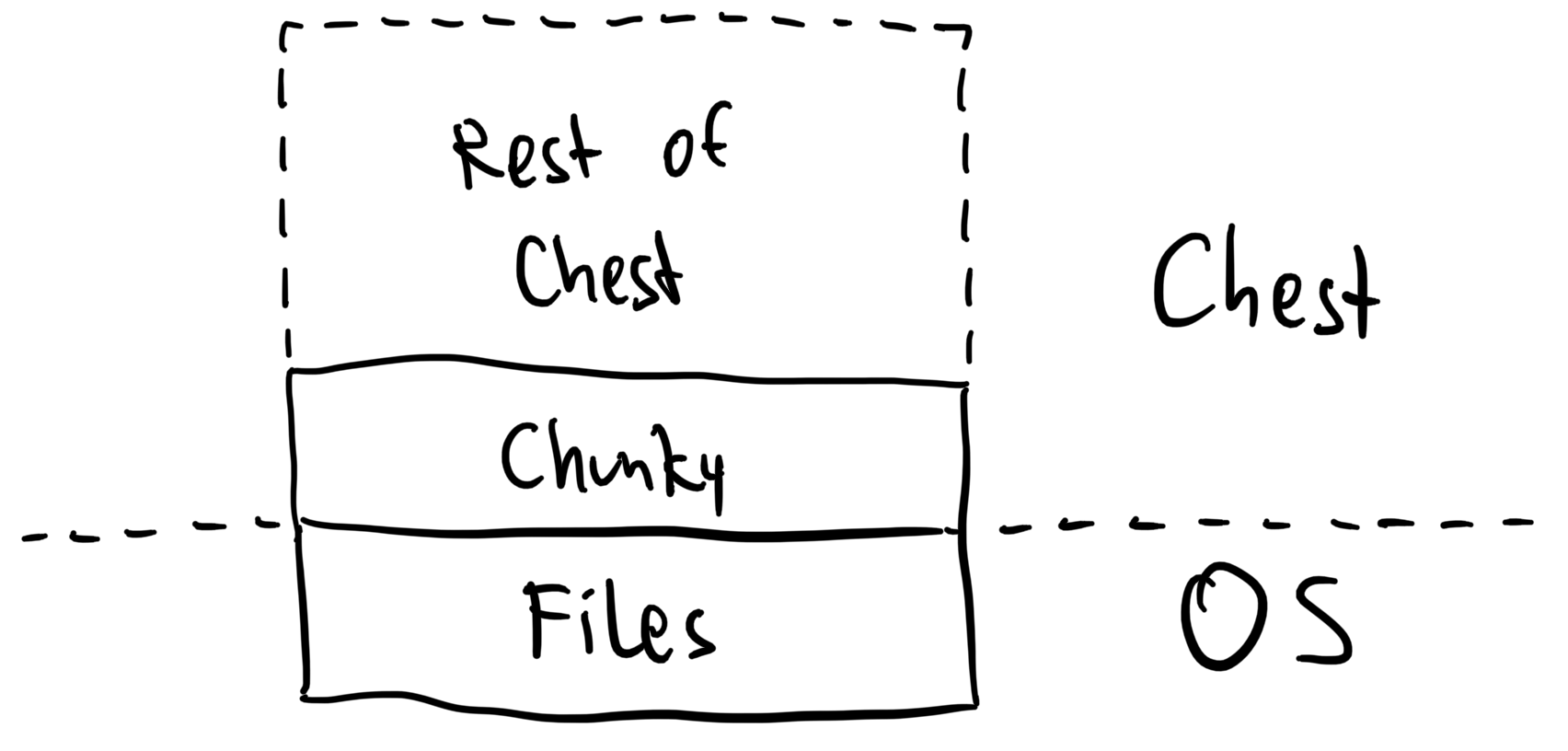
Also, writing to the file might fail for various reasons – whether the OS kills our program, the user plugs out the storage medium, the power supply vanishes, or a black hole consumes the earth. Chunky also ensures that we handle such cases gracefully by fulfilling the four ACID goals:
Atomicity: If you do a change, it's either entirely written to the database file or not at all – partially written changes should never occur.
Consistency: The database should always be in a consistent state, going from one into another.
Isolation: To all clients, it should look like they are the only client of the database.
Durability: Changes written to the database should be persistent.
Before going into how Chunky achieves these goals internally, let's give a little API overview:
The API
Chunky divides the file into chunks of a fixed size – that's the reason for its name. To do anything with those chunks, you need to start a transaction, during which you can read and change chunks. At the end of the transaction, Chunky writes all the changed chunks to the file.
Here's a schematic diagram of how the file looks like:
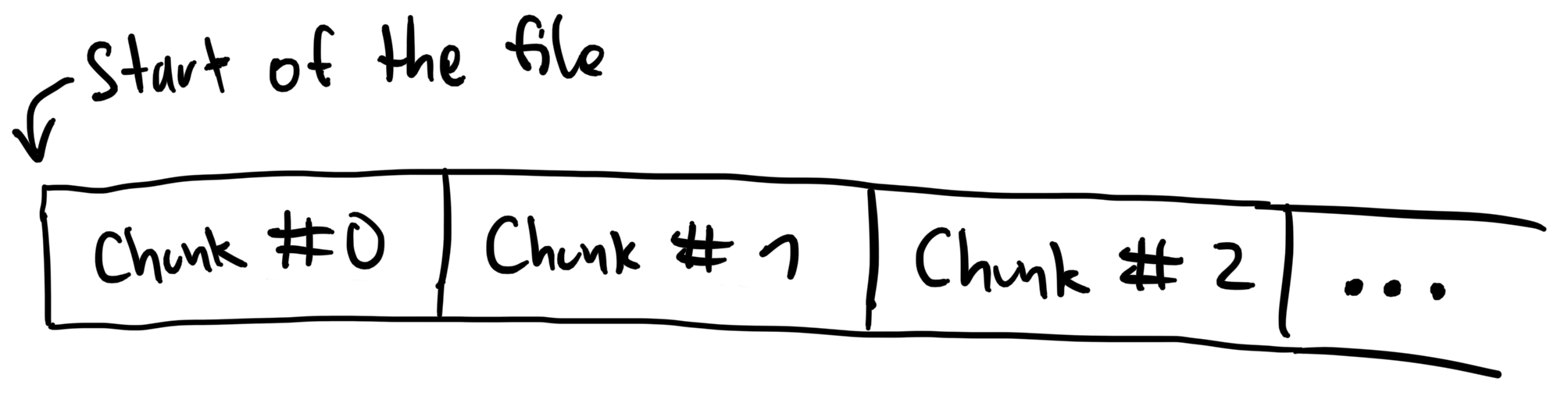
And here's how a usage might look like in actual code:
final chunky = Chunky ('🌮. chest ');
print ( chunky . numberOfChunks );
// Only using a transaction, you can interact with the chunks.
chunky . transaction (( transaction ) {
// Read the first chunk.
final chunk = await transaction [ 0 ];
// Change the first byte to 42.
chunk . setUint8 ( 0 , 42 );
// Create a new chunk.
final newChunk = transaction . reserve ();
print (' New chunk reserved at ${ newChunk . index }');
}); // At the end of the transaction, the changed chunk is written to disk.
So, how does it work?
When you call
Calling
waits for all former transactions to finish and then
starts the transaction by creating a
Transaction
A
A
When a transaction is over, Chunky compares the accessed chunks to the original version. Here's the code snippet doing just that:
// _newChunks and _originalChunks are both Maps mapping chunk indizes to chunks.
final differentChunks = _ newChunks . entries
. whereKeyValue (( index , chunk ) => !_ originalChunks . containsKey ( index ) || chunk . isDirty )
. whereKeyValue (( index , chunk ) => chunk ._ data != _ originalChunks [ index ])
. toList ();
First, it filters the chunks to
the new ones created by calling
reserve () the dirty ones (as in, they were modified using a
set ...
Then, it compares those chunks byte by bate with the original chunks – after all, if
Okay. So, how are the ACID goals achieved?
Because only one transaction is running at a time, Chunky automatically fulfills the isolation goal.
Regarding atomicity, the only guarantees that the operating system gives us are that creating and removing files is atomic and changing a single bit in a file. That's why Chunky uses a transaction file:
When a transaction finishes, a separate file is created, the naming scheme being something like
🌮.chest.transaction The file is flushed (the OS writes the changes to disk).
All changed chunks are appended to the transaction file.
The file is flushed again. Notably, this flushing doesn't affect the first byte still set to zero.
The first byte is set to one, and the file is flushed a third time. The first byte being non-zero indicates that the transaction file is complete and contains all changed chunks.
Then, the chunks in the actual
🌮.chest Afterwards, the transaction file is deleted.
If the program gets killed at any point, on the next startup, Chunky can always restore a consistent state:
Does a transaction file exist?
+---------- no yes ----------+
| |
v v
before step 1 or Is the first bit of the
after step 7 transaction file non-zero?
+-------- no yes --------+
| |
v v
before step 5; after step 5;
delete transaction file copy changes from transaction file
Because we either revert to the old state or the new one in all cases, the transactions are atomic. A transaction byte of
Conclusion
I hope you got a general idea about how the Chunky framework works internally and ensures the ACID goals. Given file transactions, we can now go on to plan what actually to store in those chunks. Stay tuned for the next article of this series.