Jupyter Energy
Increasing awareness of energy consumption in Jupyter Notebooks
Jupyter Notebooks are becoming an increasingly popular tool: These Python-based notebooks run in your browser and combine running code with writing explanatory documentation. Notebooks have a client-server architecture – even if they run on a powerful machine, you can still write your code on a light endpoint, such as a laptop. Free Jupyter Notebook services such as Google Colab make computing-intensive research fields more accessible to a general audience, but they also hide the amount of power consumed. If you're programming on your laptop, you might not even notice that the actual computing part requires a significant amount of resources in a data center. It doesn't help that Jupyter Notebooks are most commonly used in data science and Machine Learning, two of the most power-hungry disciplines. Hence, in my last semester, I developed an extension for Jupyter Notebooks that alerts you of your energy consumption.
The most similar extension is called Jupyter Resource Usage and uses
Getting the energy consumption
Unfortunately, there is no established unified way of getting information about energy consumption from the kernel. Inspired by pinpoint, an energy measurement tool developed at the Operating Systems and Middleware chair of my university, I implemented getting data from several sources. I'd also like to give a shoutout to Sven Köhler, who not only developed this tool, but also looked after me and my project specifically. He was a big help in getting started with measuring energy and had deep knowledge about how energy is measured internally and what factors might influence measurements.
These are the measurement sources I integrated into the tool:
Running Average Power Limit
Linux offers a Running Average Power Limit (RAPL for short) on x86*64 CPUs. This RAPL allows tracking of the power consumption of CPU components, such as the CPU, RAM, or built-in GPU. Notably, it doesn't include external components like external graphic cards, connected peripherals, etc.
On Linux, for each trackable metric, there are several files in
marcel@marcel-laptop:/sys/bus/event_source/devices/power/events$ ls
energy-cores energy-gpu energy-pkg energy-psys energy-ram
energy-cores.scale energy-gpu.scale energy-pkg.scale energy-psys.scale energy-ram.scale
energy-cores.unit energy-gpu.unit energy-pkg.unit energy-psys.unit energy-ram.unit
According to the Linux source code, these correspond to the following sources:
energy-cores energy-gpu energy-pkg energy-psys energy-ram
For each source, there are three files:
.../<event> energy-cores event=0x01 .../<event>.scale energy-cores.scale 2.3283064365386962890625e-10 .../<event>.unit Joules
You can use these file contents to make the Linux kernel measure how much energy the sources use. In particular, you can perform a
Here's what a minimal C program looks like that measures the energy consumption of a component:
struct perf _ event _ attr attr ; // perf_event_attr from #include <linux/perf_event.h>
memset (& attr , 0 , sizeof ( attr ));
attr . type = type ; // type from /sys/bus/event_source/devices/power/type
attr . size = sizeof ( attr );
attr . config = config ; // config from /sys/bus/event_source/devices/power/events/<event>
long fd = syscall (
__NR_ perf _ event _ open , // perf_event_open syscall
& attr ,
- 1 , // restricting to a pid is not supported
0 , // not running on a particular cpu
- 1 , // group_fd is not supported
0 // no flags
);
long int counter _ before ;
read ( fd , & counter _ before , sizeof ( long int ));
sleep ( 10 );
long int counter _ after ;
read ( fd , & counter _ after , sizeof ( long int ));
close ( fd ); // stops measuring
// scale from /sys/bus/event_source/devices/power/events/<event>.scale
double used _ energy = ( double )( counter _ after - counter _ before ) * scale ;
// unit from /sys/bus/event_source/devices/power/events/<event>.unit
printf ( "In 10 seconds, you used %0.3f %s.\n" , used _ energy , unit );
// "In 10 seconds, you used 3.458 Joules."
Microchip MCP39F511N Power Monitor
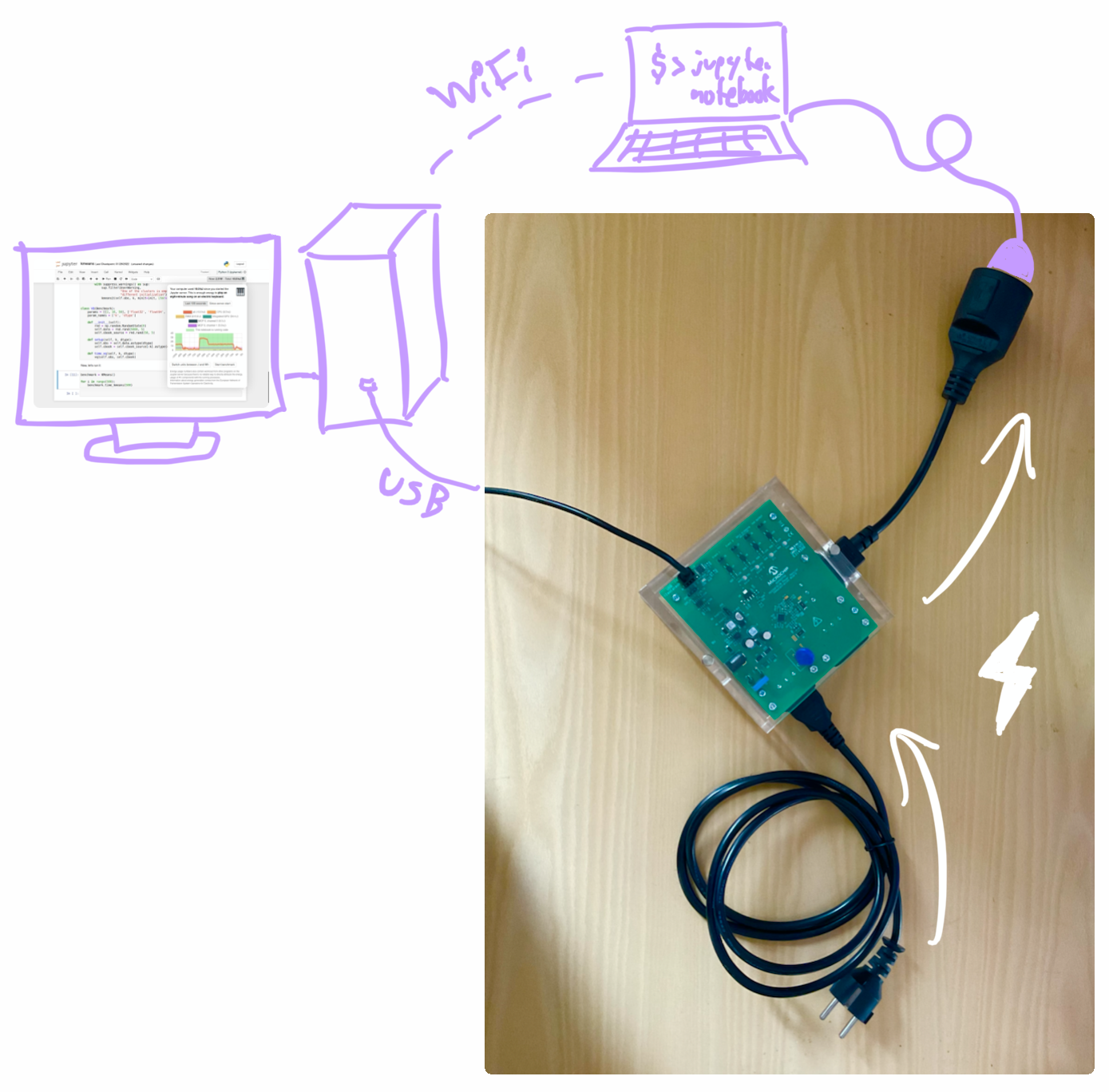
The Operating Systems and Middleware chair has a Microchip MCP39F511N Power Monitor (which we call MCP). That's actual physical hardware that you can plug between the wall socket and the computer. It then measures the power consumption of the entire system with all components, including external peripherals like connected displays, disks, or USB drives.
Here's a photo of the MCP:

When you connect the MCP's USB port to a PC, it will appear at
long fd = f511 _ init ( "/dev/ttyACM0" );
int data [ 2 ]; // The MCP has two outlets where you can measure.
int result = f511 _ get _ power (& data [ 0 ], & data [ 1 ], fd );
close ( fd );
// The MCP returns the current power consumption in 10mW steps.
double watts = 0 . 01 * ( double ) data [ 0 ];
printf ( "The MCP's first channel is currently drawing %0.3f watts.\n" , watts );
Contrary to the RAPL, the MCP only reports the power draw right now instead of a cumulative measure. Therefore, you need to continuously ask the MCP for measurements to gauge how much energy long-running tasks consume.
Nvidia Management Library
Finally, I looked at the Nvidia Management Library (NVML). In Python, the
from py3nvml import py3nvml as nvml
device = nvml . nvmlDeviceGetHandleByIndex ( gpu_index )
watts = nvml . nvmlDeviceGetPowerUsage ( device ) / 1000
It doesn't get much easier than this!
Building an Extension
Now that we know how to get the energy from several sources, we need to somehow show that data in Jupyter Notebooks. Those support two types of extensions:
server extensions: These types of extensions run in the Juypter Notebook process itself – it's running on the machine that executes the Python code. Because the Jupyter Notebook server is written in Python, you install these extensions as Python modules.
notebook extensions: These extensions run in the client's browser. They are written in JavaScript and can interact with the notebook the same way that the user can.
To record the energy data and display it, we need both types of extensions. By the way: The Jupyter Resource Usage also uses this approach – it was a helpful reference. One difference to that extension is that the
The energy server aggregates energy consumption data from multiple sources, saving both a short-term history of the power draw and a long-term recording of the energy usage. It communicates with sources in different ways: Accessing the RAPL and the MCP works best in C, so I wrote small C wrappers that can be compiled into shared libraries (with something like
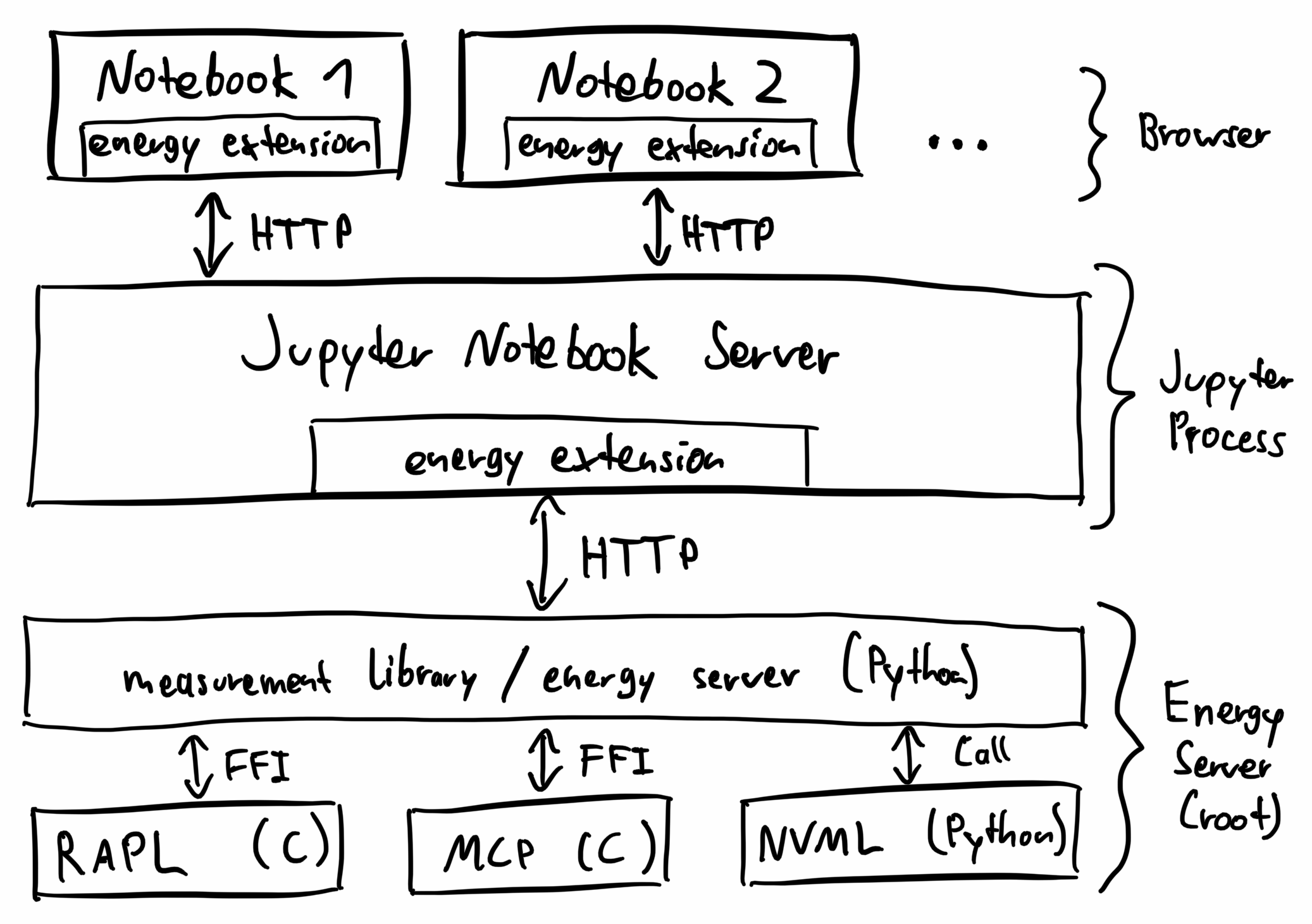
The Jupyter Energy server extension runs in the Jupyter Notebook process and communicates with the energy server using HTTP. It also registers an HTTP endpoint in the server so that the frontend can make HTTP requests to the extension.
The Jupyter Energy notebook extension runs in the browser. It adds a button to the notebook's toolbar that shows how much power the computer currently draws and how much energy it used since the notebook was opened. If you click on the button, it opens a popup with historical information.
Here's an overview of the architecture:
And here's how it looks:
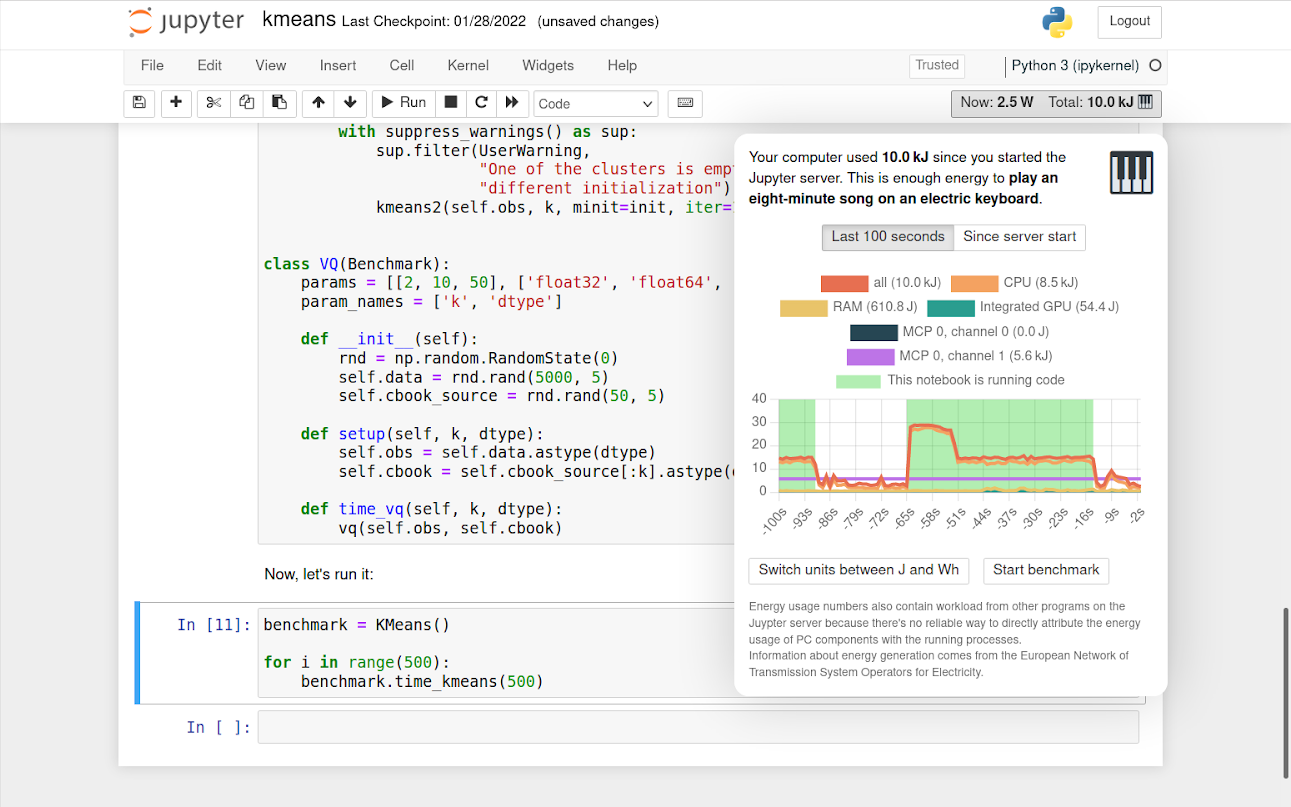
It also shows comparison values with emojis. Some of these references are from public sources (for example, how much energy the sun produces or how much energy it takes to bake a pizza). Other comparisons I measured with the MCP at home (such as the power consumption of my electric piano or water boiler).
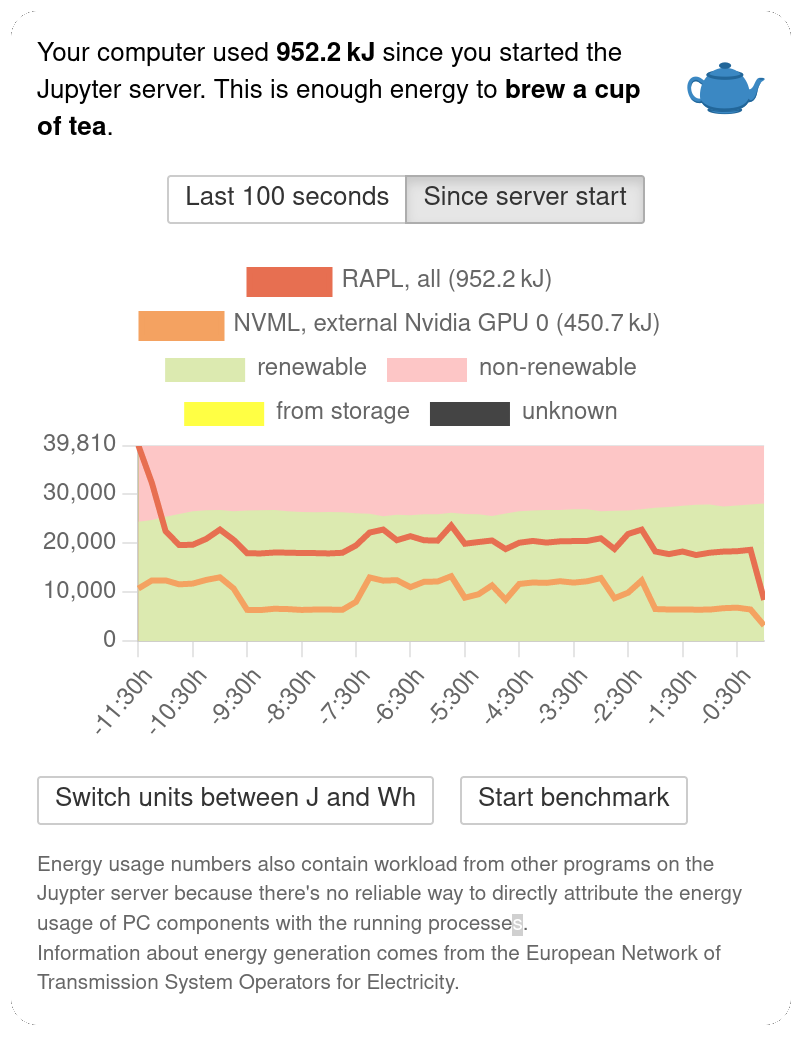
If you switch to the long-term graph, the extension shows how that energy probably got generated. Of course, the extension doesn't know your current electricity contract and can only approximate the sources. All data comes from the European Network of Transmission System Operators for Electricity (ENTS-OE). That's a collection of companies that take care of transferring energy through Europe to meet demand. All data is publicly available at transparency.entsoe.eu. The extension aggregates sources into four types:
renewables: solar, wind, biomass, geothermal, water, and waste
non-renewables: fossil and nuclear
storage sources: reservoirs
other: sources that could not be classified or that are unclear to the ENTS-OE
Currently, the extension is hardcoded to load data for Germany. In the future, it could support other countries (the data for EU countries is already public) and be more precise within a country.
Evaluation
To assess if the recorded energy consumption is accurate and to measure the overhead of measuring energy, I compared the different supported sources in some benchmarks.
I measured on my Asus ZenBook 14 laptop with Ubuntu 20.04.3. I disabled many factors that may affect energy usage and put the device into a well-defined state to get good results:
no power savings (BIOS)
fully charged
no plugs (USB, HDMI) except the power cable
full brightness on screen and keyboard
Bluetooth off
no GUI (everything in terminal mode)
I could not eliminate all factors. The biggest remaining ones are wifi (because the notebook needed to be accessible from other devices in the network) and critical system services. I ran the Jupyter Notebook on a single core (pinned using
This setup allows me to compare the internally reported energy consumption (from the RAPL) with the one measured externally (with the MCP):
To put some load on the system, I used the following benchmarks:
idle: Just running a notebook with a
sleep ( 60 ) k-means: A common clustering approach from data science that is memory-bound. I used an implementation from the SciPy benchmark.
BLAS/LAPACK: The Basic Linear Algebra Subprograms & Linear Algebra PACKage, a set of linear algebra libraries implemented for many languages. The implementation is from the SciPy benchmark as well.
bible: A benchmark querying n-grams as search terms against a rudimentary database index. This was especially interesting to me because this program comes from the Information Retrieval seminar from a previous semester when I first got in contact with Jupyter Notebooks at university.
These are the results visualized in a graph (note that the time does not start at zero):
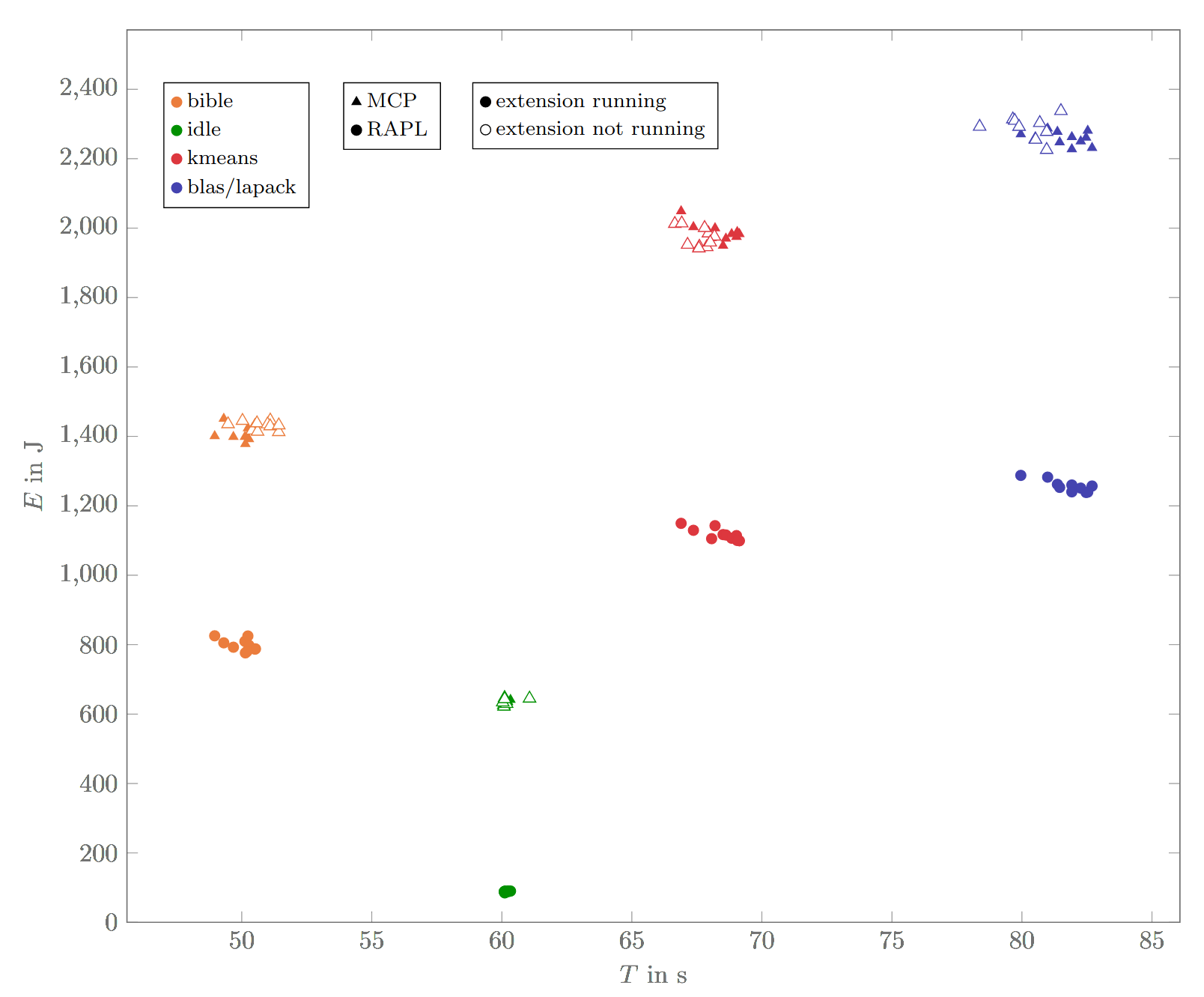
Each dot corresponds to a benchmark run that took a certain amount of time and energy. For those runs where the extension is activated, we have internal and external measurements; for those runs where it's deactivated, we only have external energy measurements.
Internal vs. external: Comparing the internal (RAPL) vs. the external (MCP) measurements, we can see that the externally measured consumption is generally higher – about seven times higher in the idle state and 1.2 to 2.0 times higher in the other benchmarks. That's expected: The RAPL only measures the CPU component; the MCP measures the power consumption of the whole laptop, including keyboard illumination, display, wifi chip, etc. In the idle state, the CPU is not used a lot, so it's only a small part of the energy usage.
With vs. without extension: The setup also allows us to compare the energy consumption and runtime with the extension enabled and disabled. This allows us to measure the overhead of measuring – measureception! Luckily, when enabling the extension, there are only minor changes in energy use (-0.7 %) and time (+0.6 %, excluding idle, +1.5 % excluding idle & bible). This indicates the extension supports everyday usage without massive energy or performance impacts.
Noisiness of benchmarks: Another observation is that the benchmarks differ in how noisy they are. The idle state is not noisy – that's because it only consists of a call to
Future Work
There are lots of areas where the extension can be improved:
Give more information about energy generation: Data about how much energy comes from wind, solar, etc. is already available. Maybe it would make sense to display that in the extension. Also, the generation estimation is currently only for Germany as a whole. It may make sense to extend this to more countries and to improve the approximation by taking into account a more precise location or even the electricity contract.
Highlight monetary motivation: You could allow the user to enter an electricity price to automatically convert the amount of energy consumed into the added cost on the electricity bill.
Make the installation easier: The installation experience can be improved by turning the extension into a package to be published on a Python package manager such as
pip Conduct user studies: An under-explored aspect is whether the extension encourages people to use less energy. A study could be conducted by having a hidden version of the extension that measures the consumption silently but discloses the results only to the study investigators. We are already in the process of inquiring if we can conduct such a study in a data science seminar – stay tuned!
If you feel like contributing, feel welcome to have a look at the repository.
Reflecting on Measuring Energy
Contrary to measuring CPU or RAM usage, measuring energy consumption is an area with less established standards – depending on the hardware, different libraries and services need to be consulted.
In another lecture this semester, we measured the energy consumption of microcontrollers instead of complex software – that was much more predictable. While you have total control over the hardware in an embedded setting, modern operating systems come with many power-saving strategies built in and you have to work against them to get reliable results. Otherwise, the operating system may seemingly randomly decide to change the CPU's clock frequency or turn on a fan.
This unpredictability of behavior also makes it hard to attribute energy consumption to individual processes: While you can count the CPU cycles spent or RAM allocated by a process, the energy usage depends on many factors. For example, the fan turning on (and thereby consuming energy) is often not the result of a single process but the interaction of many processes running simultaneously.
That being said, there would be a tremendous value to even just an approximation of the energy usage of individual processes. For instance, cloud providers currently use CPU cycles and RAM for billing purposes. A billing model based on energy consumption may better reflect their costs and encourage users to measure the energy consumption of their code. The current state of tooling for measuring the energy efficiency of code still leaves a lot to be desired.
Let's hope this changes soon – I'm looking forward to a future with more energy-aware computing.