Meta Strings
A unified syntax for raw strings and interpolation
Most programming languages have the concept of a string, a representation of text in the program. In some languages, you can even integrate code expressions in strings:
"Hello, {name}!\n"
Special characters like
This approach comes with some problems: Now, to use
"\\w\\\\+"
Every level of abstraction doubles the number of escape characters: Regexes have escape characters, and strings escape those as well. If we wanted to write a program that outputs a regex in a JSON object, it would be even more ridiculous:
Some development environments like IntelliJ offer a meta-view of a string, where you can edit the raw string and you simultaneously edit the escaped version in your program code.
Rust offers an alternative to these escape sequences: Raw strings! If you open a string not with
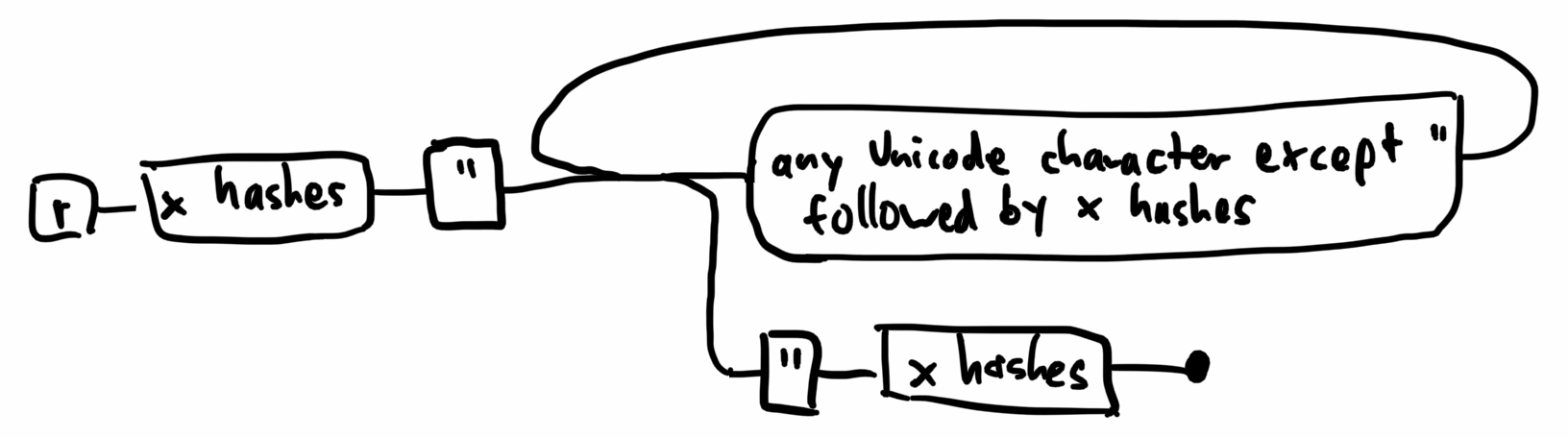
This means you can copy-paste any content into your program and use it directly in a string without escaping individual characters. Instead, you just slap a bunch of hash signs at the beginning and end, and you're ready to use those bytes you pasted as a string:
let my_program = r ## "
fn main() {
let name = r#" world "#;
println!(" \ "Hello, {}!\" , said the program . ", name);
}" ##;
This example also highlights that you can use raw strings inside of other raw strings as long as the outer one is more meta than the inner one.
We think about implementing something similar in Candy: If you start your string with
Unlike Rust's raw strings, we also want to allow string interpolation, as long as the interpolated code is wrapped in the same number of
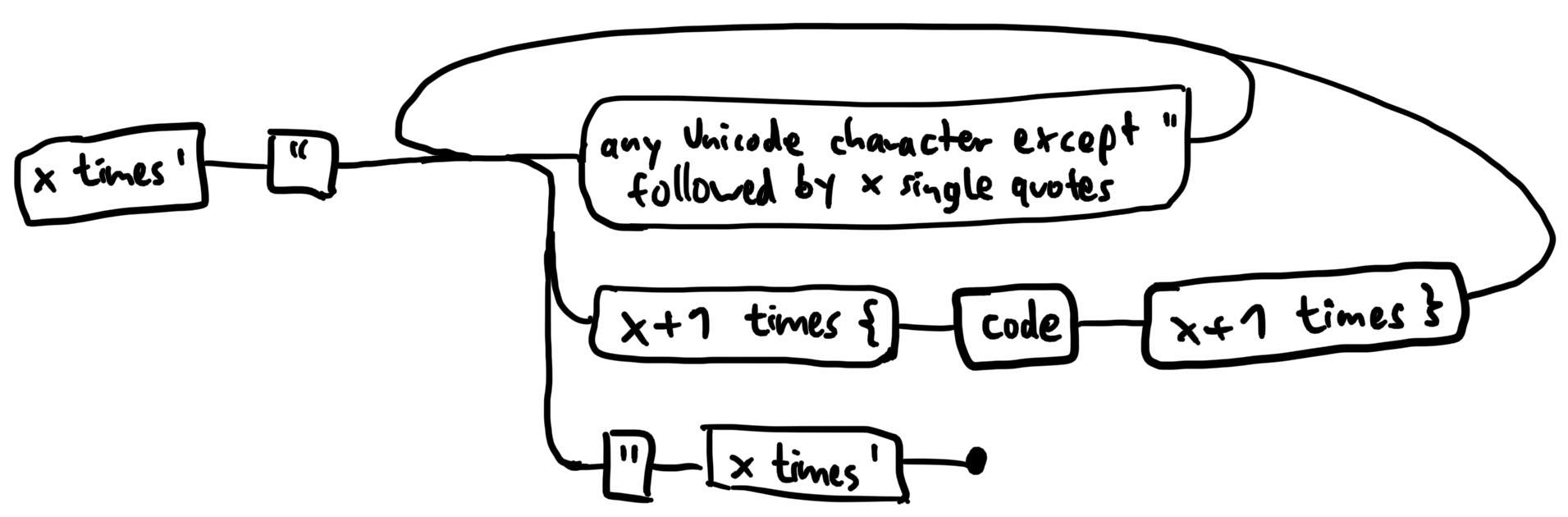
"A normal string with {interpolation}, but no double quotes."
'"A meta string can have double quotes. Here's a single one: ""'
'""Hello, {{name}}!" is what I said to {{name}}."'
''"Here's what an empty string looks like: "" This is meta meta!"''